Overview
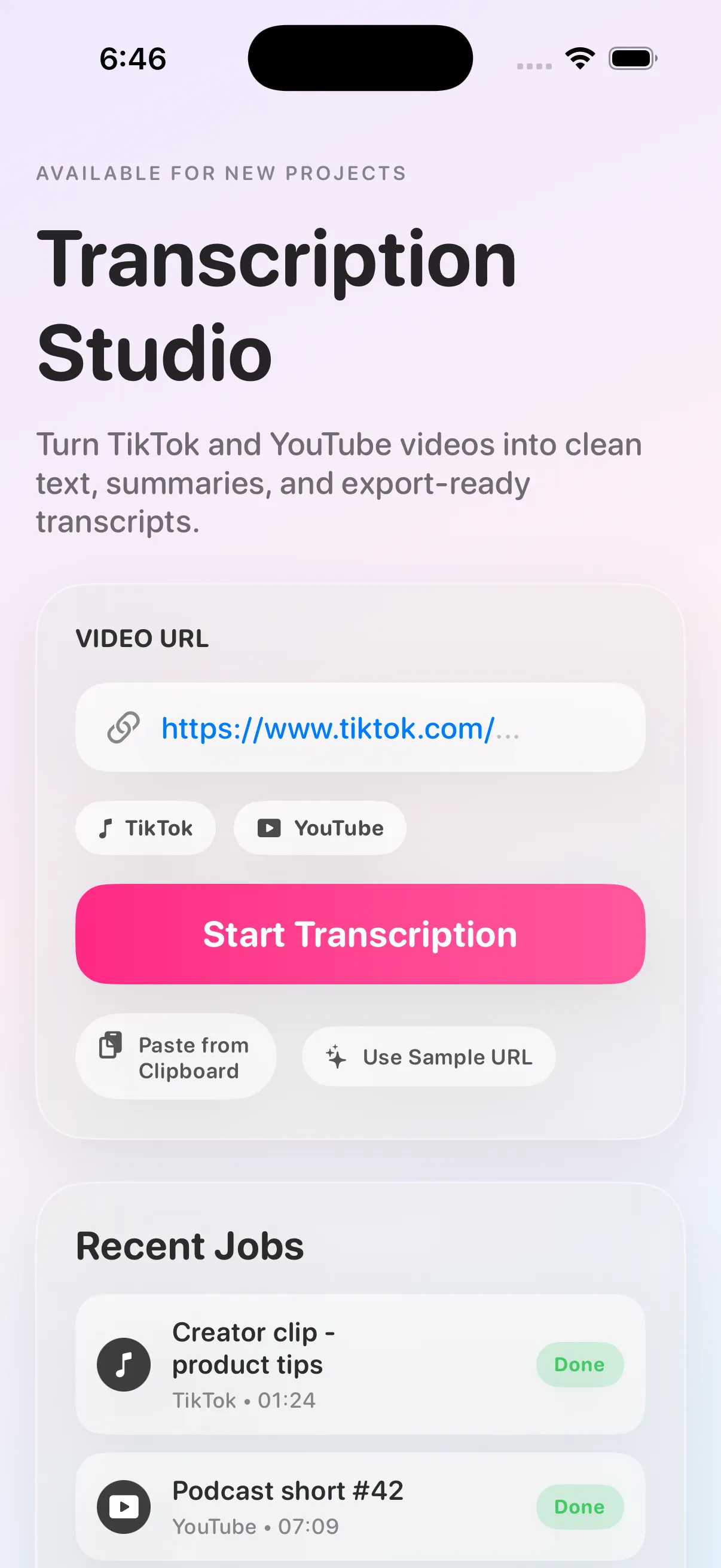
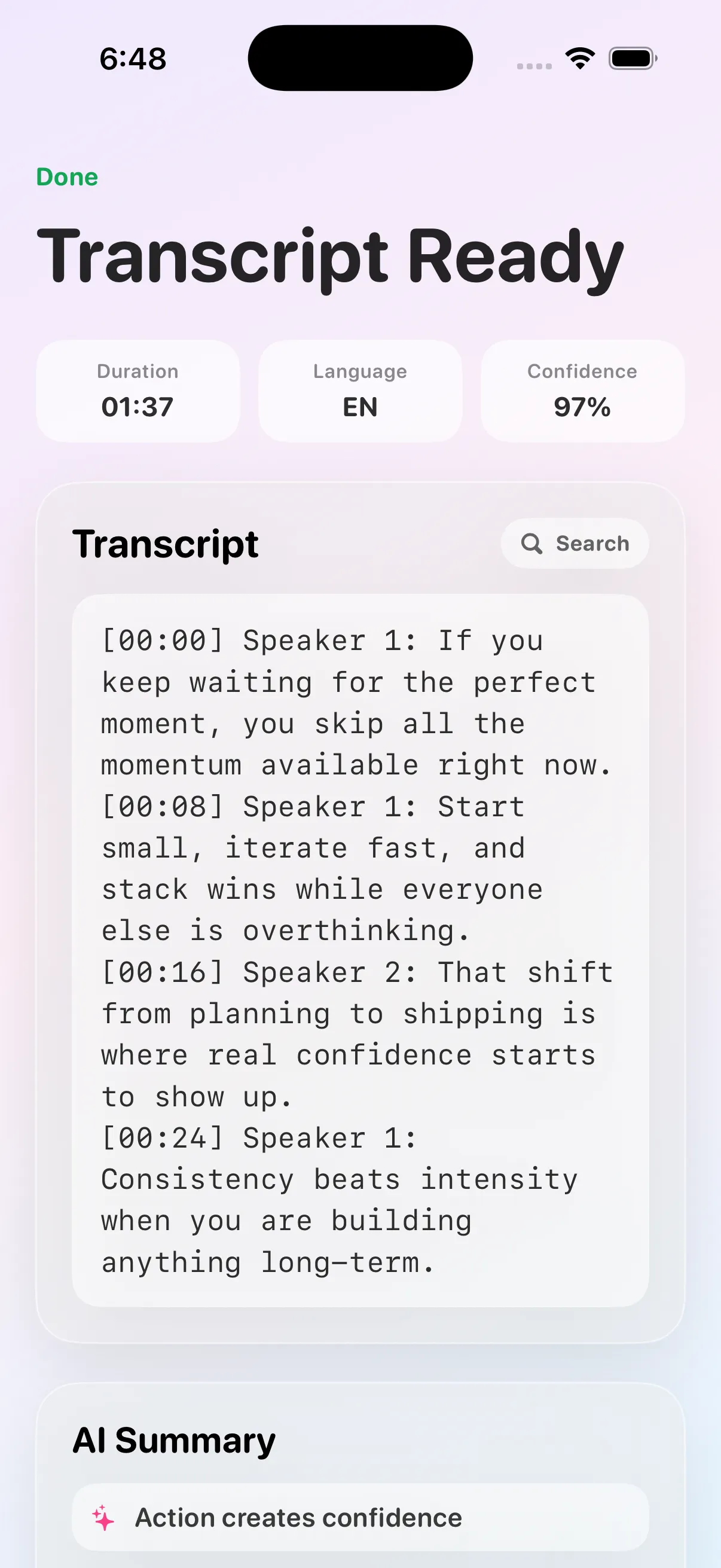
Transcribing App is a small, self-hosted web service that turns a TikTok or YouTube link — or an uploaded media file — into a clean transcript. It runs end-to-end on a single machine: a FastAPI backend coordinates the pipeline, yt-dlp and FFmpeg handle media acquisition, and Faster-Whisper does the inference locally. There is no cloud transcription provider, no API key, no audio uploaded to a third party.
The product is open source under MIT and is published as a reusable reference for anyone who wants a readable, fully-local transcription service they can self-host in an afternoon.
What this case study proves
Most one-link transcription tools either upload your audio to someone else’s infrastructure, paywall the model, or both. Transcribing App is the local-first alternative — a deliberately small service that puts the Whisper runtime on the operator’s own hardware and exposes it through a clean HTTP contract.
For FCT Technologies, the architectural lessons matter as much as the product itself: clear stage boundaries between download, transcription, and cleanup; deterministic state transitions that frontends and automations can rely on; idempotent temp-file handling so a crashed job never corrupts the next one; and configuration surfaced through environment variables so the same code runs on a Mac mini, a Linux server, or a Windows workstation without edits.
Who this is a fit for
This kind of service is a strong fit for:
- Teams handling media-heavy workflows — content operations, support documentation, research, internal knowledge capture — that want transcripts without sending audio to a third party.
- Solo operators and small studios who would otherwise pay per-minute cloud transcription fees on volumes that easily exceed the cost of running a local server.
- Compliance-sensitive deployments where audio data cannot leave the operator’s perimeter.
- Automation pipelines that need a scriptable transcription engine they can call from internal tools, scrapers, or pipelines.
It is the engine behind FCT Technologies’ own media workflows — the transcript layer for the Voice Pipeline dataset extraction step, the source of truth behind internal research notes, and the back end of every “transcribe this link” request inside our operating system.
Architecture
The service is intentionally small. Three Python modules, one static frontend, one in-memory job store.
- Ingestion —
POST /api/jobs/start accepts a URL and returns a job ID immediately. The actual download/transcribe pipeline runs as a FastAPI background task so the request returns in milliseconds. POST /api/transcribe/file accepts a multipart upload and transcribes inline, returning the transcript in the response.
- Download —
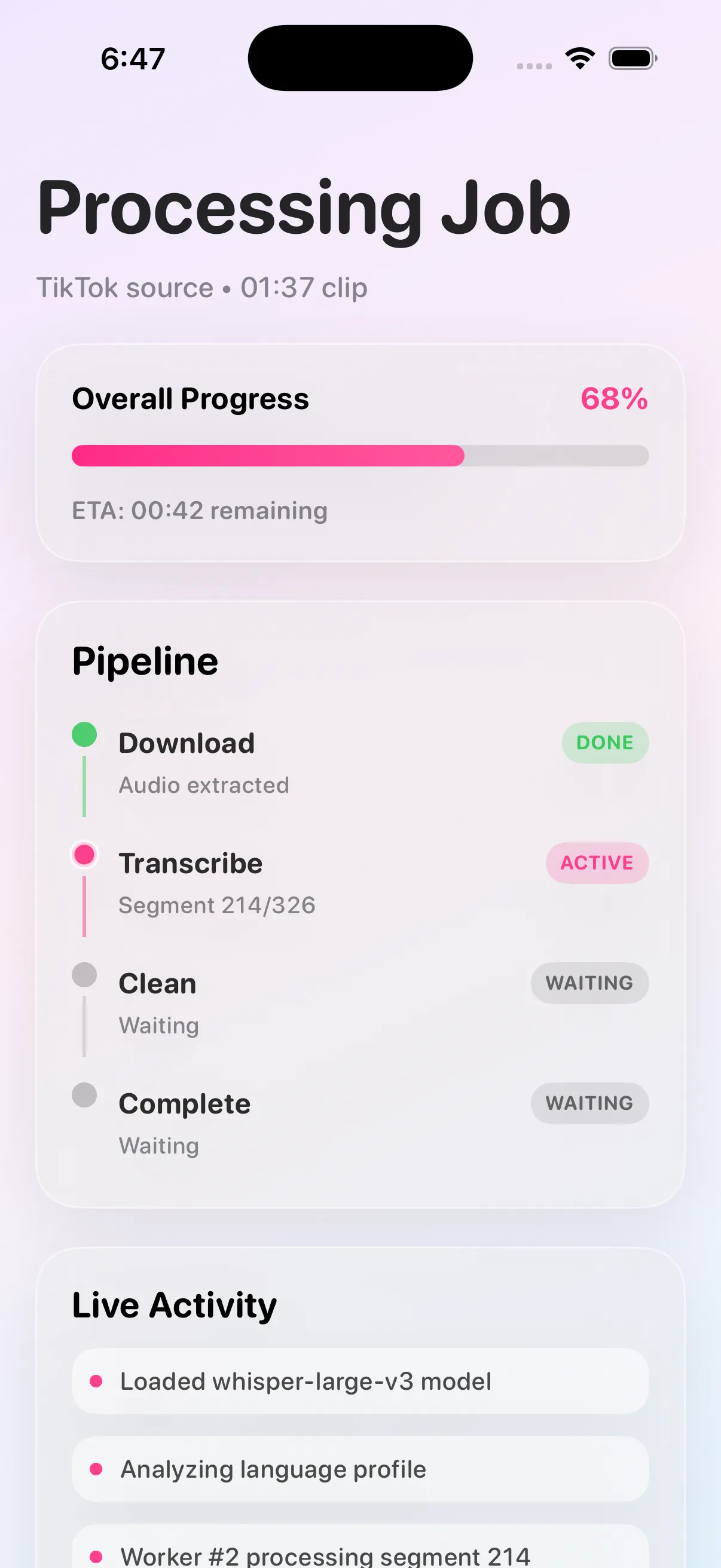
yt-dlp pulls the best available audio stream and FFmpeg extracts it as a 192 kbps MP3 into a job-scoped temp directory. The FFmpeg binary is auto-discovered via shutil.which with Homebrew, /usr/local/bin, and /usr/bin fallbacks; operators can override the location with FFMPEG_LOCATION.
- Transcribe — Faster-Whisper loads the configured model (default
base.en, int8 quantized) once at server start and reuses it across every job. Inference defaults to CPU; setting WHISPER_DEVICE=cuda and WHISPER_COMPUTE_TYPE=float16 flips it to GPU-accelerated mode with no code changes.
- Lifecycle — Each job moves through a deterministic state machine (
queued → downloading → transcribing → done | error). Progress is exposed through GET /api/jobs/{id} so the SPA can poll and the API can be wired into anything else. Temp files are cleaned per-job and on every server restart.
Job state lives in an in-memory dict keyed by UUID. Completed and failed jobs are evicted after a 24-hour retention window. The store resets on restart — that’s the right trade for a local, single-operator service.
UX and product direction
The frontend is intentionally minimal: a single page that takes a URL, shows live progress through the named stages, and reveals a copy-ready transcript when the job lands. The styling is glassmorphic with adaptive light/dark mode via light-dark() CSS color tokens, so the page feels native to whichever system theme the operator is using.
Underneath, the same backend that drives the SPA also exposes a clean JSON contract, which means the engine slots into automation pipelines, internal tooling, and other surfaces without re-implementing the transcription layer.
Why local-first matters commercially
Cloud transcription providers price per minute and route every audio file through their infrastructure. For a high-volume operator — content operations transcribing hundreds of clips a week, a research team running thousands of interview minutes, a media studio archiving every recording — those per-minute fees compound into a real line item, and the audio itself becomes someone else’s data point.
Transcribing App removes both. The runtime lives on the operator’s hardware. The audio never leaves the machine. Once installed, inference cost is electricity, and capacity scales with whatever box you point at it. For organizations evaluating custom AI software, that’s the difference between a recurring cost center and a one-time capability investment.
What’s in the repo
The full service — backend, frontend, configuration loader, pytest suite, CI workflow, security policy, and issue templates — is published at github.com/fcttechnologies/TranscribingApp under MIT license. The README documents every environment variable, includes a competitive comparison against whisper.cpp / MacWhisper / Apple Transcribe Audio / OpenAI’s hosted Whisper API, and walks through clean-machine setup on macOS, Linux, and Windows.
Operational notes
- Single-binary self-host. One
pip install -r backend/requirements.txt plus FFmpeg on PATH is the entire dependency footprint. The default install needs ~600 MB on disk including the cached base.en model.
- No authentication layer. The service is designed for
127.0.0.1 deployment. Exposing it to the public internet requires a reverse proxy and an auth shim — out of scope by design.
- Stateless restart. Job state is in-memory; restarting the server clears any in-flight jobs but does not affect completed transcripts (the SPA already has them).
- Cross-platform validated. Auto-detection of FFmpeg via
shutil.which, env-var-driven configuration, and a CI workflow running on Ubuntu cover macOS (the primary deployment target), Linux servers, and Windows workstations.
- Voice Pipeline — uses the same Faster-Whisper runtime for word-level timestamp extraction during dataset curation. The two projects share an architectural lineage: local-first, stage-isolated, deterministic state.
- Powering FCT’s internal transcription skill — every transcribed link, voice note, and Apple Developer session inside the operating system runs through this service.